Janet's ducks lay 16 eggs per day. She eats three for breakfast, bakes muffins with four, and sells the rest at the farmers' market for $2 per egg. How much does she make daily?
Unchanged at L0.
"Talk short. Drop grammar. Save token." This caveman style is widely promoted as a way to cut large-language-model inference cost, but whether it actually saves anything depends on which channel, the user's prompt or the model's response, is being compressed.
We present CAVEWOMAN, a two-channel evaluation protocol that scores every generation on task accuracy, realized per-item cost, and surface-text preservation against the model's unconstrained reference.
We evaluate nine models (GPT-5.4, GPT-4o, Claude Sonnet 4.6, Claude Haiku 4.5, Gemma-4-E4B, Kimi-K2.6, Qwen3.5, Qwen2.5-VL, and DeepSeek-R1) on five reasoning datasets (GSM8K, BoolQ, ARC-Easy, CommonsenseQA, MMLU-STEM) at five matched reduction levels, with both channels measured on the same items, for a total of 11,465 questions per model and over 1 million model evaluations across the panel.
Output compression cuts realized per-item cost across the API panel by 1.4 to 3x at the first reduction level, with the same direction of savings on all four open-weight models under public-tier pricing; the exception is GPT-5.4, whose billed cost is dominated by hidden reasoning tokens that a visible-output constraint cannot shorten. Input compression has the opposite effect, raising net cost by up to 1.8x on individual datasets at the first reduction level and 2.7x at deeper reductions, because models compensate with longer responses. Under the same setting, roughly half of correct generations no longer entail the model's unconstrained reference in surface text. The divergence survives length-controlled re-scoring, Benjamini-Hochberg multiple-comparison correction, and replication under twelve semantic measures. Robustness to compression is not predicted by model size or unconstrained accuracy.
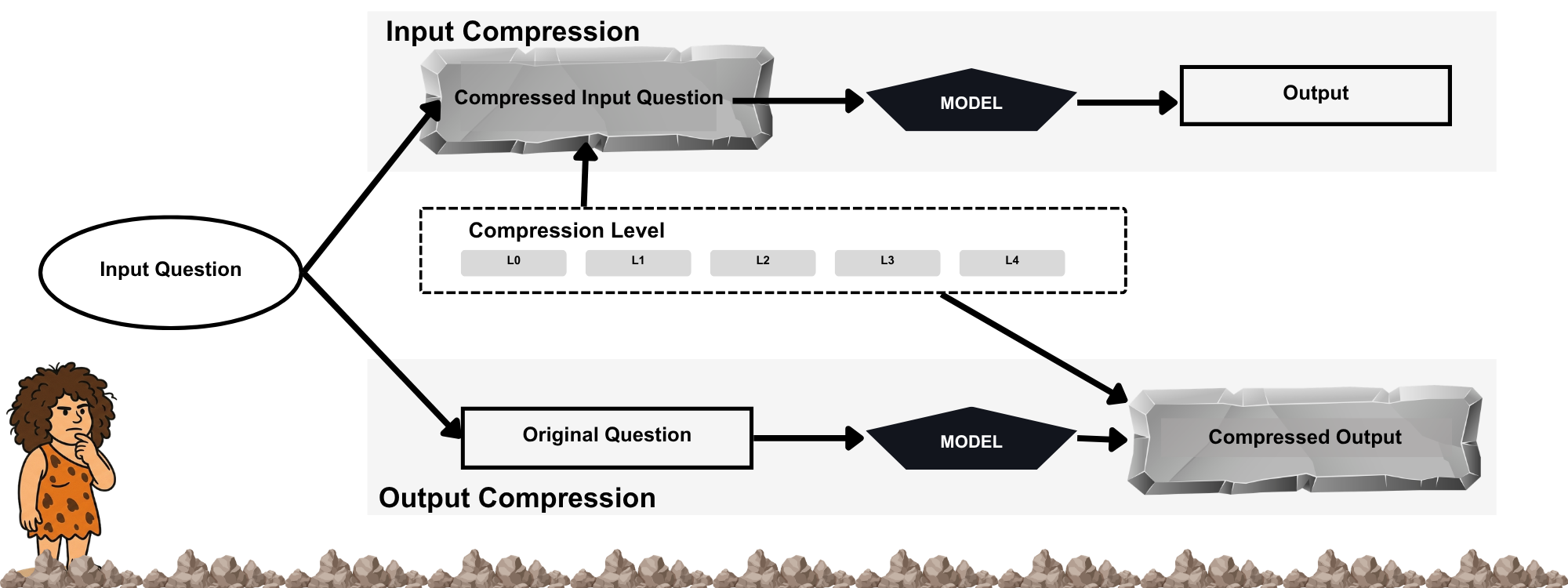
CAVEWOMAN evaluates each (model, dataset) pair under two compression channels at five matched reduction levels. The same item is passed through one channel at a time, and the only thing that changes between channels is where the constraint sits.
Channels. Condition A (input compression) filters the user prompt through a deterministic spaCy POS rule at level Lk and uses a neutral system prompt. Condition B (output constraint) leaves the user prompt verbatim and replaces the system prompt with a level-specific register restriction. Levels L0 through L4 progress from unconstrained prose to a hard 15-token budget, and both channels share the same level definitions and the same per-level output cap.
Scoring. Every generation is scored on three families of metrics. Task accuracy uses a strict answer-extraction rule, paired with a per-cell relaxed-rule audit so that wrong-format responses are not silently counted as wrong. Realized per-item cost is computed from input plus output tokens at each provider's posted list prices, rather than from prompt-token reduction alone. Reference-text preservation is measured by bidirectional NLI between each Lk response and the same item's L0 response, with twelve complementary semantic measures used as independent corroboration of the primary judge.
Statistics. Per-cell aggregates are paired with 10,000-resample bootstrap 95 percent confidence intervals at fixed seed. Across-cell comparisons use Benjamini-Hochberg FDR correction. Length-controlled NLI rescoring truncates the L0 reference to the Lk response length before scoring, and a threshold-ordering analysis confirms the channel ordering at NLI thresholds in {0.3, 0.4, 0.5, 0.6, 0.7}.
Pick a level to see its input prompt, its output prompt, and an example response.
Janet's ducks lay 16 eggs per day. She eats three for breakfast, bakes muffins with four, and sells the rest at the farmers' market for $2 per egg. How much does she make daily?
Janet's ducks lay 16 eggs per day. She eats three for breakfast, bakes muffins with four, and sells the rest at the farmers' market for $2 per egg. How much does she make daily?
Unchanged at L0.
Reason step by step in full grammatical English sentences. Conclude with the final answer on its own line in the form Answer: <answer>.
Janet has 16 eggs each day. She uses 3 for breakfast and 4 for muffins, so 7 total. That leaves 16 - 7 = 9 eggs to sell. Each sells for $2, so 9 * 2 = 18. Answer: 18
Janet's ducks lay 16 eggs day. She eats three breakfast, bakes muffins four, sells rest farmers' market $2 egg. How much does she make daily?
Function words dropped: articles, prepositions, conjunctions.
Telegraphic. No articles, conjunctions, or prepositions. Use nouns, main verbs, numbers, and standard symbols. End with Answer: <answer>.
Eggs 16 day. Breakfast 3. Muffins 4. Used 7. Remainder 16 - 7 = 9. Sell 9 * 2 = 18. Answer: 18
Janet ducks lay 16 eggs day eats three breakfast bakes muffins four sells rest farmers market $2 egg make daily
Nouns, main verbs, and numbers only.
Keyword only. Use nouns and main verbs only. No grammar, no full sentences. Output as fragments or list items.
Eggs: 16 Eat: 3, bake: 4 Used: 7 Remaining: 9 Price: $2 Total: $18 Answer: 18
Janet ducks 16 eggs day three breakfast muffins four rest farmers market $2 egg daily
Nouns and numbers only. No verbs.
Noun-phrase skeleton. No verbs of any kind. Nominal fragments, numbers, and standard symbols only.
Eggs per day: 16 Breakfast use: 3 Muffin use: 4 Total use: 7 Remainder: 9 Price per egg: $2 Daily revenue: $18 Answer: 18
Janet's ducks lay 16 eggs per day. She eats three for breakfast, bakes muffins with
First 15 whitespace tokens.
Hard 15-token budget. The entire response must be 15 tokens or fewer. Prefer the raw answer over prose.
Answer: 18
Compressing language-model inference is a two-channel problem, and accuracy alone cannot tell the channels apart. The cost story and the meaning story decouple from each other: a compressed response can be cheaper and still arrive at the right answer while no longer being a faithful representation of what the model would have said unconstrained. Single-axis evaluation can therefore mis-rank methods on the dimension that ultimately determines deployment cost.
The practical takeaway is that compression strategies should be tested at the deployment constraint, not evaluated at the unconstrained baseline, because the model ranking changes between the two. As inference becomes the dominant cost line for production language-model systems, understanding which caveman strategies actually save anything, and which only appear to on prompt-token reduction alone, is part of the engineering problem.
CAVEWOMAN is released with the complete prompt set, per-cell summaries, the validation suite, and the scripts that produced each table and figure.
We thank MIT Engaging for providing the GPU compute used to run the local-model sweep. We also acknowledge the maintainers of the open-source tools the work depends on, including spaCy, Hugging Face Transformers, and sentence-transformers.
This webpage template is adapted from Nerfies, under a CC BY-SA 4.0 License.
@misc{adeyemi2026cavewoman,
title = {CAVEWOMAN: How Large Language Models Behave Under
Linguistic Input and Output Compression},
author = {Adeyemi, Morayo Danielle and Rossi, Ryan A. and Dernoncourt, Franck},
year = {2026},
eprint = {2606.24083},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2606.24083}
}